Configure AWS S3 to Store Pipeline Logs
By default, Harness supports an embedded database for storing CI pipeline logs, suitable for evaluation or small-scale deployments. However, as deployments scale or demand grows, it’s critical to switch to a more scalable and reliable storage solution. Harness supports AWS S3 for storing CI pipeline logs, providing a secure, robust, and cost-effective way to manage large volumes of log data.
To use AWS S3, you must configure it as an external storage solution, which involves setting up an S3 bucket and connecting it to Harness by specifying the required details like the bucket name, region, and access credentials. This ensures your pipeline logs are stored securely and are easily accessible for analysis.
Create an S3 Bucket
-
Navigate to the S3 API page in the AWS Console.
-
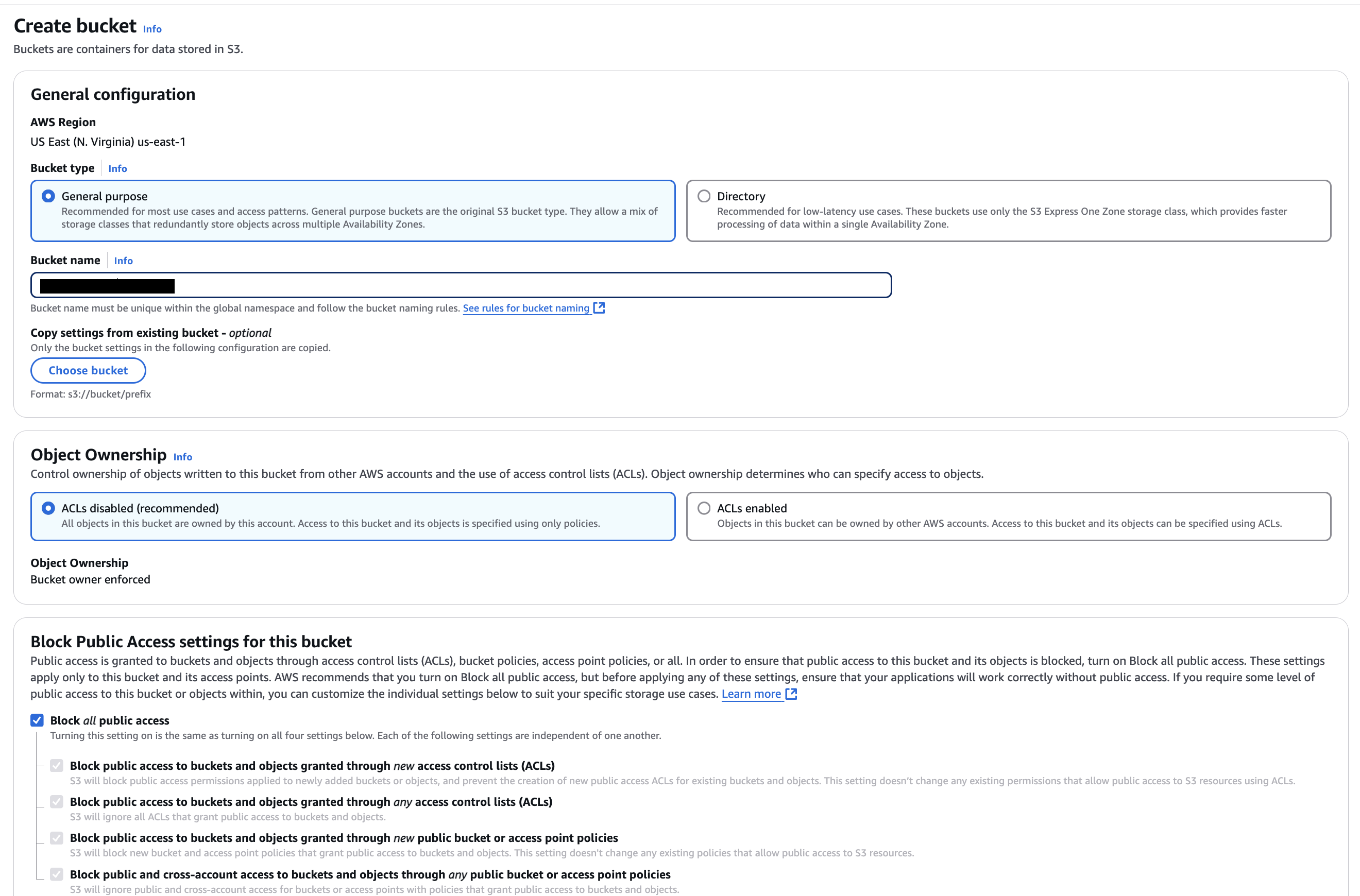
Create a General Purpose Bucket with your desired name and ensure public access is disabled.
-
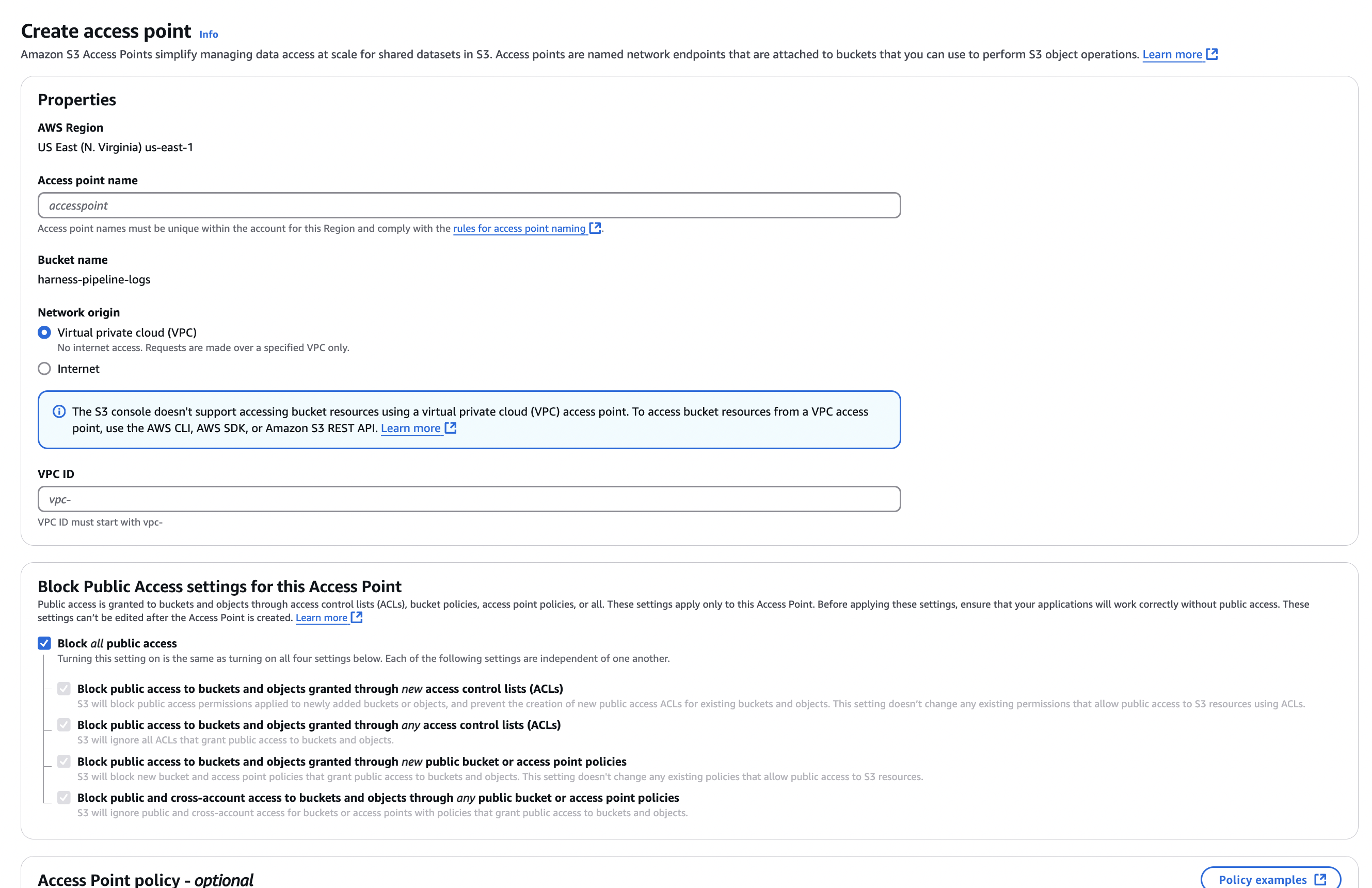
After the bucket is created, go to the Access Points tab for that bucket.
-
Add a new access point and connect it to your VPC.
Set up Access Key, Secret Key & Policy to access Bucket
To create an AWS Access Key ID and Secret Access Key with limited permissions for a specific S3 bucket, follow these steps:
-
Create a New IAM User:
- Sign in to the AWS Management Console and go to the IAM console.
- Select Users > Add user.
- Enter a user name and click Next: Set Permissions.
-
Attach Policy Directly or Add to Group:
- For direct policy attachment, choose Attach existing policies directly > Create policy.
- Use the JSON editor to specify permissions for viewing and uploading to your bucket. Replace
YOUR_BUCKET_NAMEwith your actual bucket name in the policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3-object-lambda:*"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME",
"arn:aws:s3:::YOUR_BUCKET_NAME/*"
]
}
]
}Alternatively, you can add the user to a group that already has the required permissions.
-
Review and Create User:
- After attaching the policy, proceed through Next: Tags, Next: Review, and click Create user.
-
Access Key and Secret:
- Once the user is created, you'll see the Access Key ID and Secret Access Key. Be sure to save them securely.
Create Gateway Endpoint to Connect with S3 from a Private Subnet
-
Go to the Endpoints section in the VPC page (e.g., VPC Console).
-
Click Create New Endpoint and provide the following details:
- Name:
<some-name> - Type: AWS Services
- Service:
com.amazonaws.<region>.s3(Select the Gateway type, and filter with "s3") - VPC: VPC ID of your EKS cluster
- Route Tables: Select the route tables associated with the private subnets of your VPC/EKS cluster
- Allow Full Access: Enable this option.
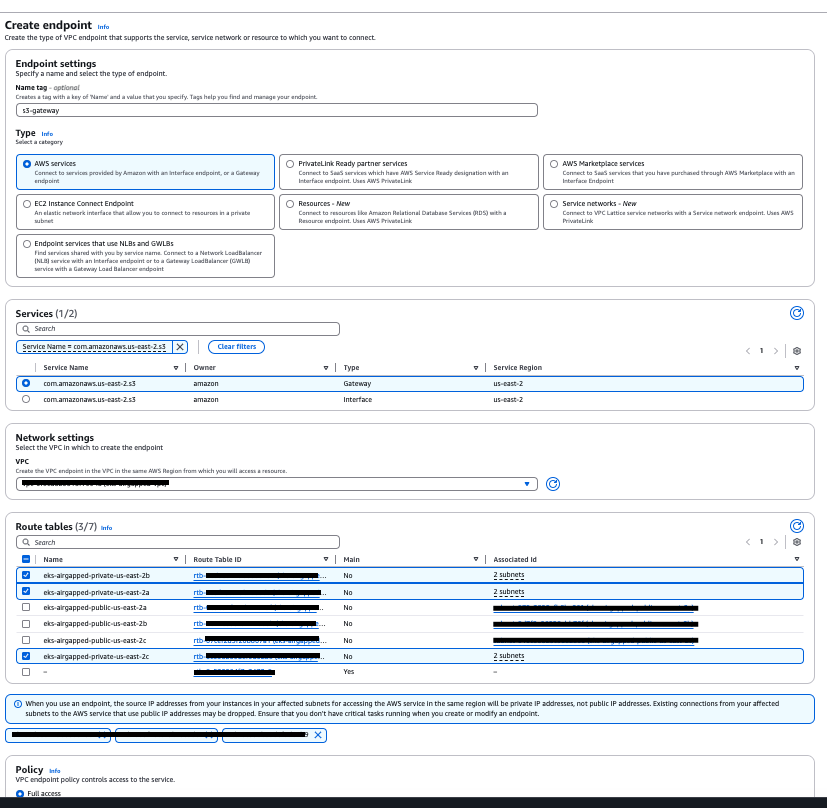
- Name:
Validate Connectivity from EKS to S3
-
Exec into Minio Pod in your Harness Namespace
Use the following command to access the Minio pod:kubectl exec -it <minio-pod> -n <namespace> -- sh -
Set Alias for S3
Set up the S3 alias with the following command:mc alias set S3 https://<bucket>.s3.<region>.amazonaws.com/ access_key secret_key -
Create a Dummy File
Create a test file with the following command:echo 'test' > /tmp/example.txt -
Copy the File to S3
Upload the dummy file to your S3 bucket:mc put /tmp/example.txt S3/example.txt -
Verify the File Exists in Your Bucket
Ensure the file was successfully uploaded by checking your S3 bucket.
Configure Harness to use S3 as Log Storage
Harness allows you to store logs in AWS S3 via the AWS S3 client. Harness supports connecting to AWS S3 using either static credentials (Access Key and Secret Key) or IAM Roles for Service Accounts (IRSA). You can choose the authentication method that best fits your security and operational requirements.
Option 1: Configure Harness - Using Static Credentials
To configure Harness to use AWS S3 for log storage using static credentials you need the S3 Access Key, S3 Secret Key, Endpoint, Region, and Bucket Name.
-
Create Kubernetes Secret to Store AccessKey and SecretKey
infoThe secrets are provided in plaintext here. If you choose to base64 encode them, use the
datafield instead ofstringData. Both methods will convert the secrets into base64-encoded format on the server.Create a Kubernetes secret in your cluster so the application can refer to it.
Use the following YAML format to store the
S3_ACCESS_KEYandS3_SECRET_ACCESS_KEY:apiVersion: v1
kind: Secret
metadata:
name: log-service-s3-secrets
namespace: <enter Namespace>
type: Opaque
stringData:
S3_ACCESS_KEY: ENTER_S3_ACCESS_KEY
S3_SECRET_ACCESS_KEY: ENTER_S3_SECRET_ACCESS_KEY -
Configure Harness Overrides to Use AWS S3
Use the following YAML format to configure the log service to use AWS S3 using the above secrets:
platform:
log-service:
s3:
# Ensure gcs.endpoint is not set when defining s3.endpoint.
endpoint: "https://s3.<bucket-region>.amazonaws.com"
# Disables Minio support and sets LOG_SERVICE_MINIO_ENABLED to false. Minio is not recommended for production.
enableMinioSupport: false
bucketName: "<bucket-name>"
region: "<bucket-region>"
secrets:
kubernetesSecrets:
- secretName: "log-service-s3-secrets" # The secret containing your AWS credentials
keys:
LOG_SERVICE_S3_ACCESS_KEY_ID: "S3_ACCESS_KEY" # Access key field in the secret
LOG_SERVICE_S3_SECRET_ACCESS_KEY: "S3_SECRET_ACCESS_KEY" # Secret access key field in the secret
Option 2: Configure Harness - Using IAM Role for Service Accounts (IRSA)
Prequisites: Your cluster must have an OIDC provider configured. If not you can follow the Configure OIDC Provider guide to configure it.
To configure Harness to use AWS S3 for log storage using IAM Role for Service Accounts (IRSA) you need Bucket Name, Bucket Policy and Region.
-
Create a Service Account with The Bucket Policy
Use the following command to create a Service Account configured with the required S3 bucket policy. This command automatically creates a new IAM Role with the specified bucket policy and attaches a trust policy that allows the Service Account to assume the role using IRSA.
eksctl create iamserviceaccount \
--name <service-account-name> \
--namespace <namespace> \
--cluster <cluster-name> \
--role-name <role-name> \
--attach-policy-arn <policy-arn> \
--approveinfoYou will need the necessary cluster, IAM and Cloudtrail permissions to successfully create the service account. Please check the Assign IAM Role to Service Account for more details.
-
Configure Harness Overrides to Use Custom Service Account
Use the following YAML format to configure the log service to use the above newly created service account.
platform:
log-service:
s3:
# leave endpoint empty to let AWS use default endpoint
endpoint: ""
enableMinioSupport: false
bucketName: "<bucket-name>"
region: "<bucket-region>"
serviceAccount:
create: false
name: "<service-account-name>" # <-- must match the SA created by eksctl above
secrets:
kubernetesSecrets: [] # No k8s secrets when using IRSA. Keep empty to avoid static keys.
Copying Data from Minio to AWS S3
If a pipeline is running during the copy command, its logs will not be transferred to S3. As a result, the execution logs for those pipelines will be lost during the transition. To ensure accuracy, Harness recommends applying a freeze window during this transition.
To transfer data from Minio to S3, execute the following commands inside the Minio pod:
mc alias set S3 https://<bucket>.s3.<region>.amazonaws.com/ access_key secret_key
mc cp --recursive local/logs/<harness-accountId> S3
Make sure to verify that the logs for existing pipelines appear correctly in the Harness UI, and that logs for new pipeline runs are stored properly.
Once confirmed, you can disable Minio by setting:
global:
database:
minio:
installed: false
Your setup for storing logs in AWS S3 is now complete.